
介绍
处理数据的过程消耗了人们在日常工作中的大量时间,而且我也经历过。我不仅处理过数值数据,还处理过文本数据,这需要大量的预处理,可以通过nltk、textblob和pyldavis等库来帮助。
下面我将讨论这些库的概述和具体的功能、关于安装的代码,以及如何使用这些有益的库的示例。
Pandas
Pandas库[3]对于致力于探索性数据分析的数据科学家来说是一个必不可少的库。顾名思义,它使用pandas来分析你的数据,或者更具体地说,pandas数据帧。
以下是一些你可以从HTML报表中访问和查看的功能:
类型推断
唯一值
缺少值
分位数统计(例如,中位数)
描述性统计
直方图
相关性(如皮尔逊)
文本分析
如何安装?
使用pip:
pip install -U pandas-profiling[notebook]jupyter nbextension enable --py widgetsnbextension这种方式对我也很管用:pip install pandas-profilingimport pandas_profiling例子:
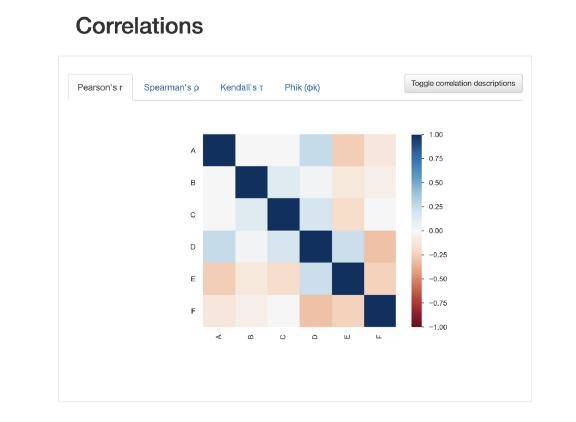
下面是我们可以从profile report功能访问的可视化示例之一。可以看到一个易于理解的彩色的相关性可视化图。
局限性:
如果有一个大的数据集,这个概要报告可能需要相当长的时间。我的解决方案是要么简单地使用较小的数据集,要么对整个数据集进行采样。
NLTK
通常与nltk相关的术语是NLP,或者自然语言处理,它是数据科学(和其他学科)的一个分支,它更容易地包含对文本的处理。导入nltk之后,你可以更轻松地分析文本。
以下是你可以使用nltk访问的一些功能:
标记化文本(例如,[“标记化”,“文本”])
词性标记
词干提取和词形还原
如何安装:
pip install nltkimport nltk例子:
import nltkthing_to_tokenize = “a long sentence with words”tokens = nltk.word_tokenize(thing_to_tokenize)tokensreturns:[“a”, “long”, “sentence”, “with”, “words”]我们需分开每个单词,以便对其进行分析。
在某些情况下需要分隔单词。然后它们可以被标记、计数,机器学习算法的新指标可以使用这些输入来创建预测。利用nltk的另一个有用的特性是文本可以用于情感分析。情感分析在很多企业中都很重要,尤其是那些有客户评论的企业。现在我们讨论情感分析,让我们看看另一个有助于快速情感分析的库。
TextBlob
TextBlob[8]与nltk有很多相同的优点,但是它的情感分析功能非常出色。除了分析之外,它还具有利用朴素贝叶斯和决策树支持分类的功能。
以下是你可以使用TextBlob访问的一些功能:
标记化
词性标注
分类
拼写更正
情感分析
如何安装:
pip install nltkimport nltk例子:
情感分析:
review = TextBlob(“here is a great text blob about wonderful Data Science”)review.sentimentreturns:Sentiment(polarity=0.80, subjectivity = 0.44)正常浮点范围为[-1.0,1.0],而积极情感介于[0.0,1.0]之间。
分类:
from textblob.classifiers import NaiveBayesClassifiertraining_data = [(‘sentence example good one’, ‘pos’), (‘sentence example great two’, ‘pos’), (‘sentence example bad three’, ‘neg’), (‘sentence example worse four’, ‘neg’)]testing_data = [(‘sentence example good’, ‘pos’), (‘sentence example great’, ‘pos’)]cl = NaiveBayesClassifier(training_data)你可以使用这个分类器对文本进行分类,该分类器将返回“pos”或“neg”输出。
这些来自textblob的简单代码提供了非常强大和有用的情感分析和分类。
pyLDAvis
另一个使用NLP的工具是pyLDAvis[10]。它是一个交互式主题模型可视化工具的库。例如,当我使用LDA(潜Dirichlet分布)执行主题模型时,我通常会看到单元格中的主题输出,这可能很难阅读。然而当它出现在一个很好的视觉总结中时,它会更有益,也更容易消化,就像pyLDAvis一样。
以下是你可以使用pyLDAvis访问的一些功能:
显示了前30个最突出的术语
有一个交互式调整器,允许你滑动相关性度量
显示x轴上的PC1和y轴上的PC2的热门主题
显示与大小对应的主题
总的来说,这是一种让人印象深刻的主题可视化方式,这是其他任何库都无法做到的。
如何安装:
pip install pyldavisimport pyldavis例子:
为了看到最好的例子,这里有一个Jupyter Notebook[11]参考资料,它展示了这个数据科学库的许多独特和有益的特性: https://nbviewer.jupyter.org/github/bmabey/pyLDAvis/blob/master/notebooks/pyLDAvis_overview.ipynb
NetworkX
这个数据科学包NetworkX[13],将其优势集中在生物、社会和基础设施网络可视化上。
以下是你可以使用NetworkX访问的一些功能:
创建图形、节点和边
检验图的元素
图结构
图的属性
多重图
图形生成器和操作
如何安装:
pip install networkximport networkx例子:
创建图形
import networkxgraph = networkx.Graph()你可以与其他库协作,例如matplotlib.pyplot也可以创建图形的可视化(以数据科学家习惯于看到的方式)。
总结
如你所见,有很多有用的数据科学库可以很容易地访问。本文对一些探索性的数据分析库、自然语言处理库(NLP)和图形库做了一些说明。

0 评论