
HTTP基础
一、URL与资源
URL即统一资源定位系统,它定义了用户所需的特定资源,它位于何处以及如何获取它。大多数的URL方案的语法都建立在由9个部分构成的通用格式上: <scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag> 其中最重要的是方案(scheme,指明协议)、主机(host)和路径(path)。
URL是使用US-ASCII字符集进行编码的,因此部分字符需要转义后再重新编码
二、HTTP报文
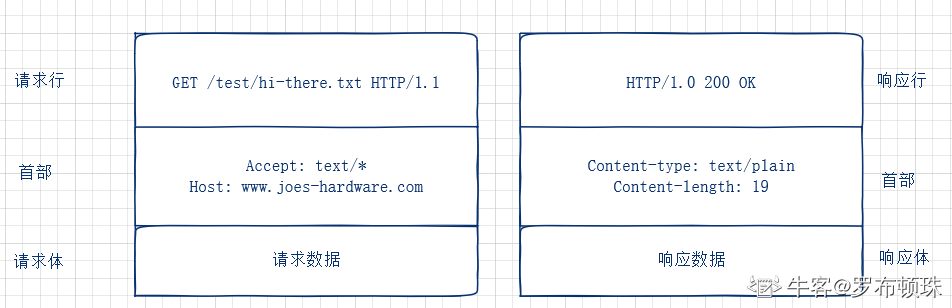
1、请求和响应报文结构
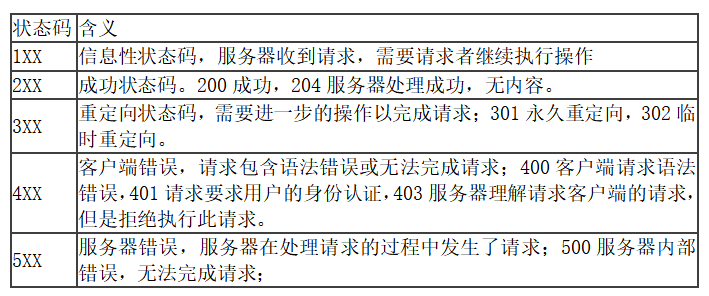
2、状态码
3、请求方法
GET 请求指定的页面信息,并返回实体主体
HEAD 类似于GET请求,只不过返回的响应体,用于获取报头。
POST 向指定的资源提交数据进行处理请求。数据被包含在请求体中。POST请求可能会导致新的资源的建立或已有资源的修改。
PUT 从客户端向服务端传送的数据取代指定的文档的内容
DELETE 请求服务器删除指定的页面
CONNECT HTTP/1.1协议中预留给能将连接改为管道方式的代理服务器
OPTIONS 允许客户端查看服务端的性能
TRACE 回显服务端收到的请求,主要用于测试或诊断
PATCH 是对PUT方法的补充,用来对已知资源进行局部更新。
首部
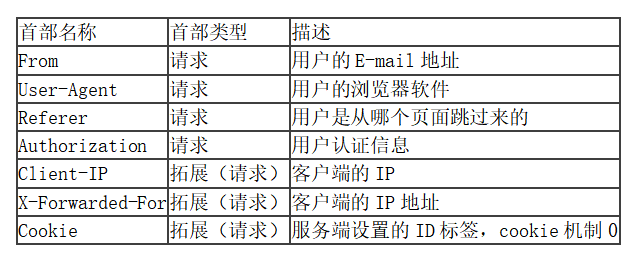
1.Allow 服务器支持哪些请求方法
2.Content-Encoding 文档的编码方式
3.Content-Length 表示内容的长度。只有当浏览器使用持久HTTP连接时才需要这个数据。
4.Content-Type 表示后面的文档属于什么MIME类型
5.Date 当前的GMT时间
6.Expires 应该在什么时候认为文档已经过期,从而不再缓存它。
7.Last-Modified 文档的最后改动时间。
8.Location 表示客户应当到哪里去提取文档
9.Set-Cookie 设置和页面关联的Cookie
三、连接管理
TCP连接
HTTP连接实际上就是TCP连接和一些使用连接的规则。
由于TCP协议导致的HTTP性能瓶颈:
TCP连接建立握手
TCP慢启动拥塞控制
数据聚集的Nagle算法
用于捎带确认的TCP延迟确认算法
TIME_WAIT时延和端口耗尽
HTTP连接
1.并行连接
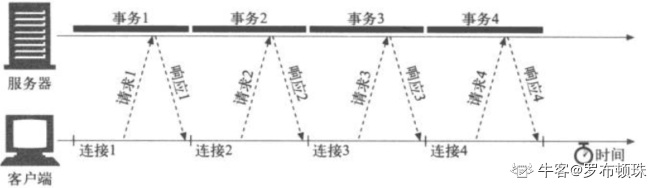
通过多条TCP连接发起并发的HTTP请求. 并行连接可能会提高页面加载的速度,但是多连接会导致资源的消耗,在带宽竞争激烈的时候性能提升有限。
2.持久连接
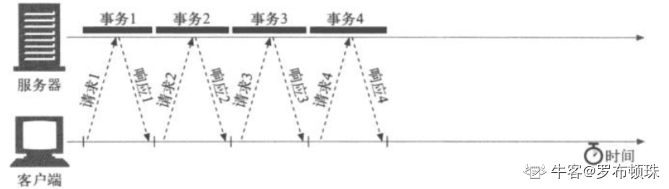
重用TCP连接,以消除连接及关闭时延。 HTTP/1.1允许HTTP设备在事务处理结束之后将TCP连接保持在打开状态,以便为未来的HTTP请求重用现存的连接。重用已对目标服务打开的空闲持久化连接,就可以避开缓慢的连接建立阶段和慢启动的拥塞适应阶段。
3.管道化连接
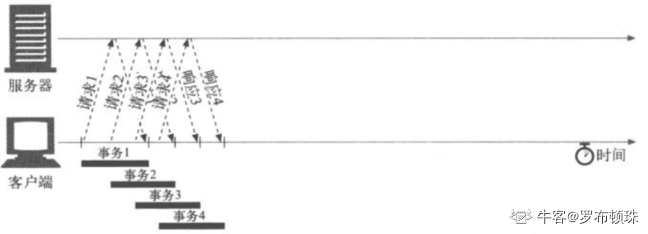
通过共享的TCP连接发起并发的HTTP请求 HTTP/1.1允许在持久连接上可选地使用请求管道。这是在keep-alive连接上地进一步性能优化。在响应到达之前,可以将多条请求放入队列。当第一条请求通过完了流向另一端地服务器时,第二条和第三条请求也可以开始发送了。在高时延网络条件下,这样做可以降低网络的回环时间,提高性能。
4.复用的连接 交替传送请求和响应报文(实验阶段)
客户端识别与cookie机制
HTTP最初是一个匿名的、无状态的请求/响应协议。但是在有些场景下我们需要对用户进行跟踪(个性化、推荐、管理信息的存档、记录会话)。
用户识别机制主要有以下几种:
(1)承载用户身份信息的HTTP首部 用于承载用户身份信息的首部有这些:
(2)客户端的IP地址跟踪,通过用户的IP地址对其进行识别 使用IP地址进行跟踪已经是一个比较落后的做法。原因在于IP地址描述的是机器而不是用户,且由于代理和NAT的存在,导致IP地址不再准确。
(3)用户登录,用认证方式识别用户 用户登录后利用首部的Authorization进行用户标识。
(4)胖URL,一种在URL嵌入识别信息的技术 在URL中添加用户标识,该方案主要用于无法使用cookie时。 该方案的局限性在:
URL变得复杂,可读性变差
无法共享URL,URL包含了用户和会话信息
破环缓存。为每个URL生成特定的版本就意味着不再有可供公共访问的URL需要缓存了
额外的服务器负载。服务器需要重写URL,给服务器带来了新的负载
逃逸口,当用户跳转到其他URL后,可能导致原有URL中的信息丢失
在会话间是非持久的,下次进入网站URL中的信息都会丢失
(5)cookie机制 当服务器想要标识用户时,会再响应首部中添加一个Set-Cookie来设置cookie。之后的每次请求都会携带该cookie值。出于安全考虑可以将Cookie设置为httpOnly,禁止js读取。
cookie的分类:
会话cookie:是一种临时的cookie,浏览器关闭后会话cookie就会被删除
持久cookie:持久cookie存储在磁盘上,浏览器关闭后下次启动该cookie依然存在,持久cookie就是设置了过期时间的cookie
四、HTTP高级
1、代理
web上的代理服务器是代表客户端完成事务处理的中间人。代理服务器按照是否被客户端共享可以被分为公共代理和私有代理。
代理和网关的对比:
代理是连接是两个或多个使用相同协议的应用程序,而网关连接的则是两个或多个使用不同协议的端点。
网关扮演的是“协议转换器”
代理的用处:
内容过滤器
文档访问控制
安全防火墙
Web缓存:代理缓存维护了常用文档的本地副本,并将它们按需提供,以减少缓慢且昂贵的因特网通信
反向代理:代理可以假扮web服务器,这些反向代理接受发给web服务器的真实请求,但与web服务器不同的是,他们可以发起与其他服务器的通信,以便按需定位所请求的内容。
内容路由器
转码器
匿名者代理
几种代理服务器的部署方式:
出口代理
访问入口代理
反向代理
网络交换代理
代理获得流量的方式:
修改客户端
修改网络。在网络基础设施中对HTTP流量进行监控,然后对其拦截,将流量导入代理中
修改DNS命名空间
修改Web服务器,由Web服务器重定向来完成流量导入
2、缓存
web缓存时可以自动保存常见文档副本的HTTP设备。当web请求抵达缓存时,如果本地由“已缓存的”副本,就可以从本地存储设备而不是元素服务器中提取这个文档。
缓存的优点:
减少了冗余的网络传输
缓解了网络瓶颈问题
减低了对原始服务器的要求
降低了距离时延
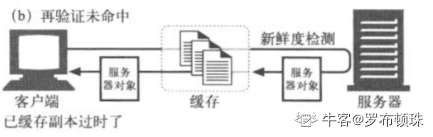
命中和未命中: 原始服务器的内容可能会发生变化,缓存要不时对其进行检测,看看他们保存的副本是否仍然时服务器上最新的副本。这种操作被称为 HTTP再验证 。
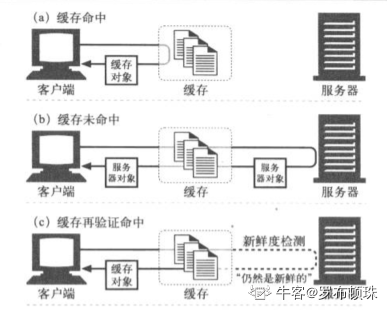
缓存对缓存的副本进行再验证时,会向原始服务器发送一个小的再验证请求。如果内容没有变化,服务器会以一个小的304 Not Modified进行响应。如果再验证未命中,则服务器向客户端发送一条普通的、带有完整内容的HTTP 200 OK响应。如果对象被删除,则服务器回送一个404 Not Found。
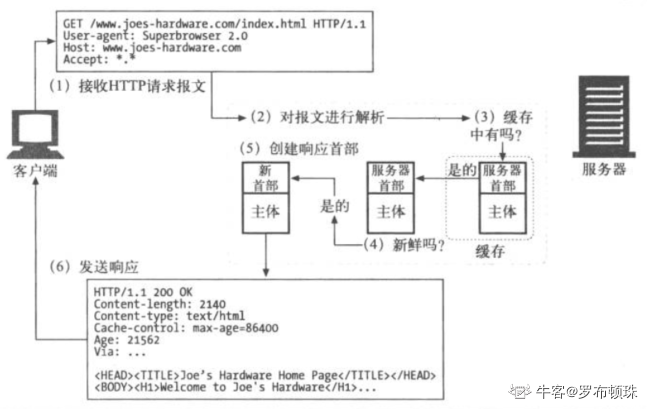
缓存的处理步骤:
接受:缓存从网络中读取抵达的请求报文
解析:缓存对报文进行解析,提取出URL和各种首部
查询:缓存查看是否有本地副本可用,如果没有,就获取一份副本
新鲜度检测:缓存查看已缓存副本是否足够新鲜,如果不是,就询问服务器是否有任何更新
创建响应:缓存会用新的首部和已缓存的主体来构建一条响应
发送:缓存通过网络将响应发回给客户端
日志:缓存可选地创建一个日志文件条目来描述这个事务
内容协商
一个URL通常需要代表若干不同的资源,比如不同的语言的版本,因此HTTP提供了内容协商方法,允许从一个URL中表示的不同资源中做选择。
内容协商的分类:
服务器驱动的协商:服务器自动判定
透明协商:让中间代理来选择
内容协商相关的首部:

*参考书籍《HTTP权威指南》*
作者:罗布顿珠

0 评论